[TOC]
关于CGI和FastCGI的理解
阅读目录
在搭建 LAMP/LNMP 服务器时,会经常遇到 PHP-FPM、FastCGI和CGI 这几个概念。如果对它们一知半解,很难搭建出高性能的服务器。
0.CGI的引入
在网站的整体架构中,Web Server(如nginx,apache)只是内容的分发者,对客户端的请求进行应答。
如果客户端请求的是index.html这类静态页面,那么Web Server就去文件系统中找对应的文件,找到返回给客户端(一般是浏览器),在这里Web Server分发的就是是静态数据。
整个过程如下图:
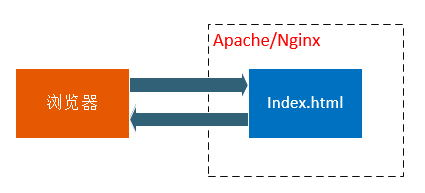
对于像index.php这类的动态页面请求,Web Server根据配置文件知道这个不是静态文件,则会调用PHP 解析器进行处理然后将返回的数据转发给客户端(浏览器)。
整个过程如下图:
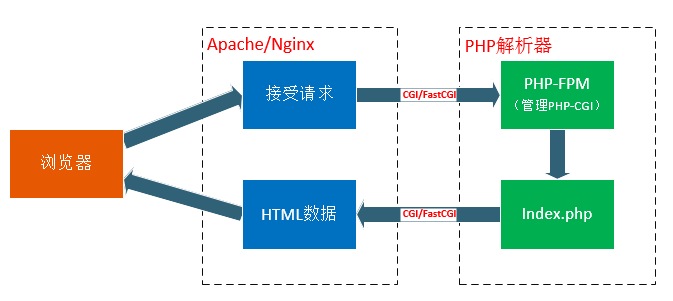
在这个过程中,Web Server并不能直接处理静态或者动态请求,对于静态请求是直接查找然后返回数据或者报错信息,对于动态数据也是交付给其他的工具(这里的PHP解析器)进行处理。
那么Web Server和处理工具(这里的php-fpm)是怎样进行交互的呢?传输的是那些数据呢?这些数据的格式又是怎样的呢?
由此便引出了今天的主角:CGI
1.关于CGI
1.1.什么是CGI?
1)CGI(Common Gateway Interface)全称是“通用网关接口”,是一种让客户端(web浏览器)与Web服务器(nginx等)程序进行通信(数据传输)的协议。
用来规范web服务器传输到php解释器中的数据类型以及数据格式,包括URL、查询字符串、POST数据、HTTP header等,也就是为了保证web server传递过来的数据是标准格式的。
2)CGI可以用任何一种具有标准输入、输出和环境变量的语言编写,如php、perl、tcl等。
不同类型语言写的程序只要符合cgi标准,就能作为一个cgi程序与web服务器交互,早期的cgi大多都是c或c++编写的。
3)一般说的CGI指的是用各种语言编写的能实现该功能的程序。
1.2.CGI程序的工作原理
1)每次当web server收到index.php这种类型的动态请求后,会启动对应的CGI程序(PHP的解析器);
2)PHP解析器会解析php.ini配置文件,初始化运行环境,然后处理请求,处理完成后将数据按照CGI规定的格式返回给web server然后退出进程;
3)最后web server再把结果返回给浏览器。
1.3.CGI程序的特点
1)高并发时的性能较差:
CGI程序的每一次web请求都会有启动和退出过程,也就是最为人诟病的fork-and-execute模式(每次HTTP服务器遇到动态请求时都需要重新启动脚本解析器来解析php.ini,重新载入全部DLL扩展并重初始化全部数据结构,然后把结果返回给HTTP服务器),很明显,这样的接口方式会导致php的性能很差,在处理高并发访问时,几乎是不可用的。
2)传统的CGI接口方式安全性较差
3)CGI对php.ini的配置很敏感,在开发和调试的时候相当方便
1.4.CGI程序的应用领域
因为CGI为每一次请求增加一个进程,效率很低,所以基本已经不在生产部署时采用。但由于CGI对php配置的敏感性,通常被用在开发和调试阶段
2.关于FastCGI
2.1.什么是FastCGI?
通过CGI程序的工作原理可以看出:CGI程序性能较差,安全性较低,为了解决这些问题产生了FastCGI。
1)FastCGI(Fast Common Gateway Interface)全称是“快速通用网关接口”
是通用网关接口(CGI)的增强版本,由CGI发展改进而来,主要用来提高CGI程序性能,
类似于CGI,FastCGI也是一种让交互程序与Web服务器通信的协议
2)FastCGI致力于减少网页服务器与CGI程序之间互动的开销,从而使服务器可以同时处理更多的网页请求(提高并发访问)。
3)同样的,一般说的FastCGI指的也是用各种语言编写的能实现该功能的程序。
2.2.FastCGI程序的工作原理
1)Web Server启动同时,加载FastCGI进程管理器(nginx的php-fpm或者IIS的ISAPI或Apache的Module)
2)FastCGI进程管理器读取php.ini配置文件,对自身进行初始化,启动多个CGI解释器进程(php-cgi),等待来自Web Server的连接。
3)当Web Server接收到客户端请求时,FastCGI进程管理器选择并连接到一个CGI解释器。Web server会将相关环境变量和标准输入发送到FastCGI子进程php-cgi进行处理
4)FastCGI子进程完成处理后将数据按照CGI规定的格式返回给Web Server,然后关闭FastCGI子进程或者等待下一次请求。
2.3.FastCGI对进程的管理方式
Fastcgi会先启一个master,解析配置文件,初始化执行环境,然后再启动多个worker。当请求过来时,master会传递给一个worker,然后立即可以接受下一个请求。这样就避免了重复的劳动,效率自然提高。而且当worker不够用时,master可以根据配置预先启动几个worker等着;当然空闲worker太多时,也会停掉一些,这样就提高了性能,也节约了资源。这就是fastcgi的对进程的管理。
2.4.FastCGI的特点:
1)FastCGI具有语言无关性,支持用大多数语言进行编写,对应的程序也支持大多数主流的web服务器
FastCGI技术目前支持语言有:C/C++,Java,PHP,Perl,Tcl,Python,SmallTalk,Ruby等。
支持FastCGI技术的主流web服务器有:Apache,Nginx,lighttpd等
2)FastCGI程序的接口方式采用C/S结构,可以将web服务器和脚本解析服务器分开,独立于web服务器运行,提高web服务器的并发性能和安全性:
提高性能:这种方式支持多个web分发服务器和多个脚本解析服务器的分布式架构,同时可以在脚本解析服务器上启动一个或者多个脚本解析守护进程来处理动态请求,可以让web服务器专一地处理静态请求或者将动态脚本服务器的结果返回给客户端,这在很大程度上提高了整个应用系统的性能。
提高安全性:API方式把应用程序的代码与核心的web服务器链接在一起,这时一个错误的API的应用程序可能会损坏其他应用程序或核心服务器,恶意的API的应用程序代码甚至可以窃取另一个应用程序或核心服务器的密钥,采用这种方式可以在很大程度上避免这个问题
3)FastCGI的不依赖于任何Web服务器的内部架构,因此即使服务器技术的变化, FastCGI依然稳定不变
4)FastCGI程序在修改php.ini配置时可以进行平滑重启加载新配置
所有的配置加载都只在FastCGI进程启动时发生一次,每次修改php.ini配置文件,只需要重启FastCGI程序(php-fpm等)即可完成平滑加载新配置,已有的动态请求会继续处理,处理完成关闭进程,新来的请求使用新加载的配置和变量进行处理
5)FAST-CGI是较新的标准,架构上和CGI大为不同,是用一个驻留内存的服务进程向网站服务器提供脚本服务。像是一个常驻(long-live)型的CGI,维护的是一个进程池,它可以一直执行着,只要激活后,不会每次都要花费时间去fork一次(这是CGI最为人诟病的fork-and-execute 模式),速度和效率比CGI大为提高,是目前的主流部署方式。
6)FastCGI的不足:
因为是在内存中同时运行多进程,所以会比CGI方式消耗更多的服务器内存,每个PHP-CGI进程消耗7至25兆内存,在进行优化配置php-cgi进程池的数量时要注意系统内存,防止过量
2.5.FastCGI程序的应用领域
生产环境的主流部署方式
2.6.关于CGI和FastCGI的总结
1)CGI 和 FastCGI 都只是一种通信协议规范,不是一个实体,一般说的CGI指的是用各种语言编写的能实现该功能的程序
2)CGI 程序和FastCGI程序,是指实现这两个协议的程序,可以是任何语言实现这个协议的。(PHP-CGI 和 PHP-FPM就是实现FastCGI的程序)
3)CGI程序和FastCGI程序的区别:
关于CGI程序:
CGI使外部程序与Web服务器之间交互成为可能。CGI程序运行在独立的进程中,并对每个Web请求建立一个进程,这种方法非常容易实现,但效率很差,难以扩展。面对大量请求,进程的大量建立和消亡使操作系统性能大大下降。此外,由于地址空间无法共享,也限制了资源重用。
关于FastCGI程序:
与CGI程序为每个请求创建一个新的进程不同,FastCGI使用持续的进程(master)来处理一连串的请求。这些进程由FastCGI服务器管理,而不是web服务器。 当进来一个请求时,web服务器把环境变量和这个页面请求通过一个socket或者一个TCP connection传递给FastCGI进程。
3.关于PHP-CGI,PHP-FPM和Spawn-FCGI
3.1.PHP-CGI是什么?
很多地方说:PHP-CGI是PHP自带的FastCGI管理器,目前还没找到最原始的出处,以我的理解和经验来看这话有点毛病,我认为应该是:使用php实现CGI协议的CGI程序,可以用来管理php解释器,如果有异议可以和我探讨下。。。
使用如下命令可以启动PHP-CGI:
1 | php-cgi -b 127.0.0.1:9000 |
php-cgi的特点:
1)php-cgi变更php.ini配置后需重启php-cgi才能让新的配置生效,不可以平滑重启
2)直接杀死php-cgi进程php就不能运行了
3.2.关于php-fpm
PHP-FPM(FastCGI Process Manager)
针对PHP-CGI的不足,PHP-FPM和Spawn-FCGI应运而生,它们的守护进程会平滑从新生成新的子进程。
1)PHP-FPM使用PHP编写的PHP-FastCGI管理器,管理对象是PHP-CGI程序,不能说php-fpm是fastcgi进程的管理器,因为前面说了fastcgi是个协议
下载地址:http://php-fpm.org/download
早期的PHP-FPM是作为PHP源码的补丁而使用的,在PHP的5.3.2版本中直接整合到了PHP-FPM分支,目前主流的PHP5.5,PHP5.6,PHP5.7已经集成了该功能(被官方收录)
在配置时使用–enable-fpm参数即可开启PHP-FPM
2)修改php.ini之后,php-cgi进程的确是没办法平滑重启的。php-fpm对此的处理机制是新的worker用新的配置,已经存在的worker处理完手上的活就可以歇着了,通过这种机制来平滑过度。
3.3.关于Spawn-FCGI
1)Spawn-FCGI是一个通用的FastCGI管理服务器,它是lighttpd中的一部份,很多人都用Lighttpd的Spawn-FCGI进行FastCGI模式下的管理工作
2)Spawn-FCGI目前已经独成为一个项目,更加稳定一些,也给很多Web 站点的配置带来便利。已经有不少站点将它与nginx搭配来解决动态网页。
Spawn-FCGI的下载地址是http://redmine.lighttpd.net/projects/spawn-fcgi,目前(20190114)最新版本为1.6.4,在4年前更新的,有点凉凉的意思。。。
3.4.PHP-FPM与spawn-CGI对比
1)PHP-FPM的配置都是在php-fpm.ini的文件内,早些时候重启可以通过/usr/local/php/sbin/php-fpm reload进行,无需杀掉进程就可以完成php.ini的修改加载,被php官方收录以后需要指定参数进行重载配置,可以自己创建脚本进行管理
2)PHP-FPM控制的进程cpu回收的速度比较慢,内存分配的很均匀,比Spawn-FCGI要好,可以有效控制内存和进程,且不容易崩溃,很优秀
3)Spawn-FCGI控制的进程CPU下降的很快,而内存分配的比较不均匀。有很多进程似乎未分配到,而另外一些却占用很高。可能是由于进程任务分配的不均匀导致的。而这也导致了总体响应速度的下降。而PHP-FPM合理的分配,导致总体响应的提到以及任务的平均。
(摘录的,暂未实际验证)
4.PHP运行的5种模式
php目前比较常见的五大运行模式:包括cli、cgi 、fast-cgi、isapi、apache模块的DLL
4.1.cli模式
cli模式就是php的命令行运行模式,
例如:在linux下经常使用 “php -m”查找PHP安装了那些扩展就是PHP命令行运行模式
其他的可以输入php -h查看下
4.2.CGI模式
比较经典的使用方法,使用CGI程序将浏览器,web服务器,php解释器连接起来进行数据交换的工具,目前主要用来做开发或调试
CGI方式在遇到连接请求(用户 请求)先要创建cgi的子进程,激活一个CGI进程,然后处理请求,处理完后结束这个子进程。这就是fork-and-execute模式。所以用cgi方式的服务器有多少连接请求就会有多少cgi子进程,子进程反复加载是cgi性能低下的主要原因。都会当用户请求数量非常多时,会大量挤占系统的资源如内 存,CPU时间等,造成效能低下。
4.3.FastCGI模式
目前主流的使用方式,比CGI模式的工具效率高很多,大量用于分布式高并发的环境中
在Linux中,nginx加php-fpm是最主流的使用方式
4.4.ISAPI运行模式
ISAPI即Internet Server Application Program Interface,是微软提供的一套面向Internet服务的API接口,一个ISAPI的DLL,可以在被用户请求激活后长驻内存,等待用户的另一个请求,还可以在一个DLL里设置多个用户请求处理函数,此外,ISAPI的DLL应用程序和WWW服务器处于同一个进程中,效率要显著高于CGI。(由于微软的排他性,只能运行于windows环境)
4.5.apache模块运行模式
此运行模式可以在Linux和windows环境下使用Apache,他们的共同点都是用 LoadModule 来加载相关模块,有两种类型
4.5.1.mod_php模块
Apache调用php的相关模块(php5_module),也就是把php作为apache的一个子模块来运行
当通过web访问php文件时,apache就会调用php5_module通过sapi将数据传给php解析器来解析php代码,整个过程如下图:
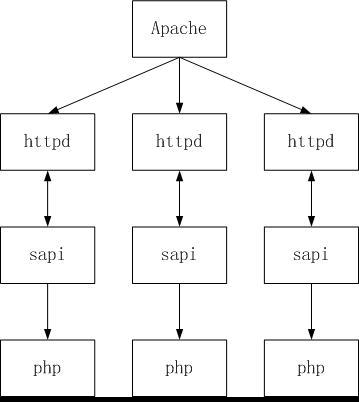
从上面图中,可以看出:
1)sapi就是这样的一个中间过程,SAPI提供了一个和外部通信的接口,有点类似于socket,使得PHP可以和其他应用进行交互数据(apache,nginx等)。
php默认提供了很多种SAPI,常见的提供给apache和nginx的php5_module、CGI、FastCGI,给IIS的ISAPI,以及Shell的CLI。
所以,以上的apache调用php执行的过程如下:
1 | apache -> httpd -> php5_module -> sapi -> php |
2)apache每接收一个请求,都会产生一个进程来连接php通过sapi来完成请求,如果用户过多,并发数过多,服务器就会承受不住了。
3)把mod_php编进apache时,出问题时很难定位是php的问题还是apache的问题,而且PHP是与Web服务器一起启动并运行的,当php模块出现问题可能会导致Apache一同挂掉
4.5.2.mod_cgi模块
在此种模式中Apache启动加载mod_cgi模块,使用CGI调用管理动态的php请求
更高级的是mod_fcgid模块,是apache的fastcgi实现,性能提高,在apache的2.4以后的版本中得到支持。
总结:
1)mod_php是apache的内置php解释模块,使用prefork方式,不需要额外的进程来做通讯和应用解释,显然mod_php比mod_cgi这样方式性能要好得多
2)缺点是把应用和HTTP服务器绑定在了一起,当php模块出现问题可能会导致Apache一同挂掉
3)另外每个Apache进程都需要加载mod_php而不论这个请求是处理静态内容还是动态内容,这样导致浪费内存,效率下降,
4)php.ini文件的变更需要重新启动apache服务器才能生效,这使得无法进行平滑配置变更。
4.6.总结一下
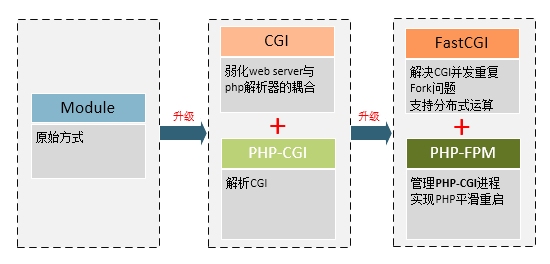
随着技术的不断升级,单纯的Apache加php模块的方式已不再主流,而是替换为Apache加php_cgi,以及后来的php_fcgi和nginx加php-fpm的方法,可以看下图:
5.参考文章:
CGI、FastCGI和PHP-FPM关系图解:https://www.awaimai.com/371.html
关于CGI 和 PHP-FPM需要弄清的:http://www.cleey.com/blog/single/id/848.html
浅谈PHP fastcgi和php-fpm:https://www.jianshu.com/p/d095cbcbcf1b
php五大运行模式CGI,FAST-CGI,CLI,ISAPI,APACHE模式浅谈:https://www.cnblogs.com/XACOOL/p/5619650.html
==== 完毕,呵呵呵呵 ====
感恩,互助,分享。




